

一、正则表达式:
(Regular Expression, RE):是通过一些特殊字符的排列,用”搜寻/取代/删除“ 一列或多列文字字串
分级:正则表达式的字串表示方式依照不同的严谨度分为:基础正则表达式与延伸正则表达式
ps:延伸正则表达式除了可以处理一组字串外还可以处理群组字串
ps:==正则表达式和万用字符完全不同==!万用字符是bash操作接口的一个功能。正则表达式是字串处理方式
1.基础正则表达式
前提:首先要确定正则表达式使用的语系!!!(否则结果不一定正确)
例如: 
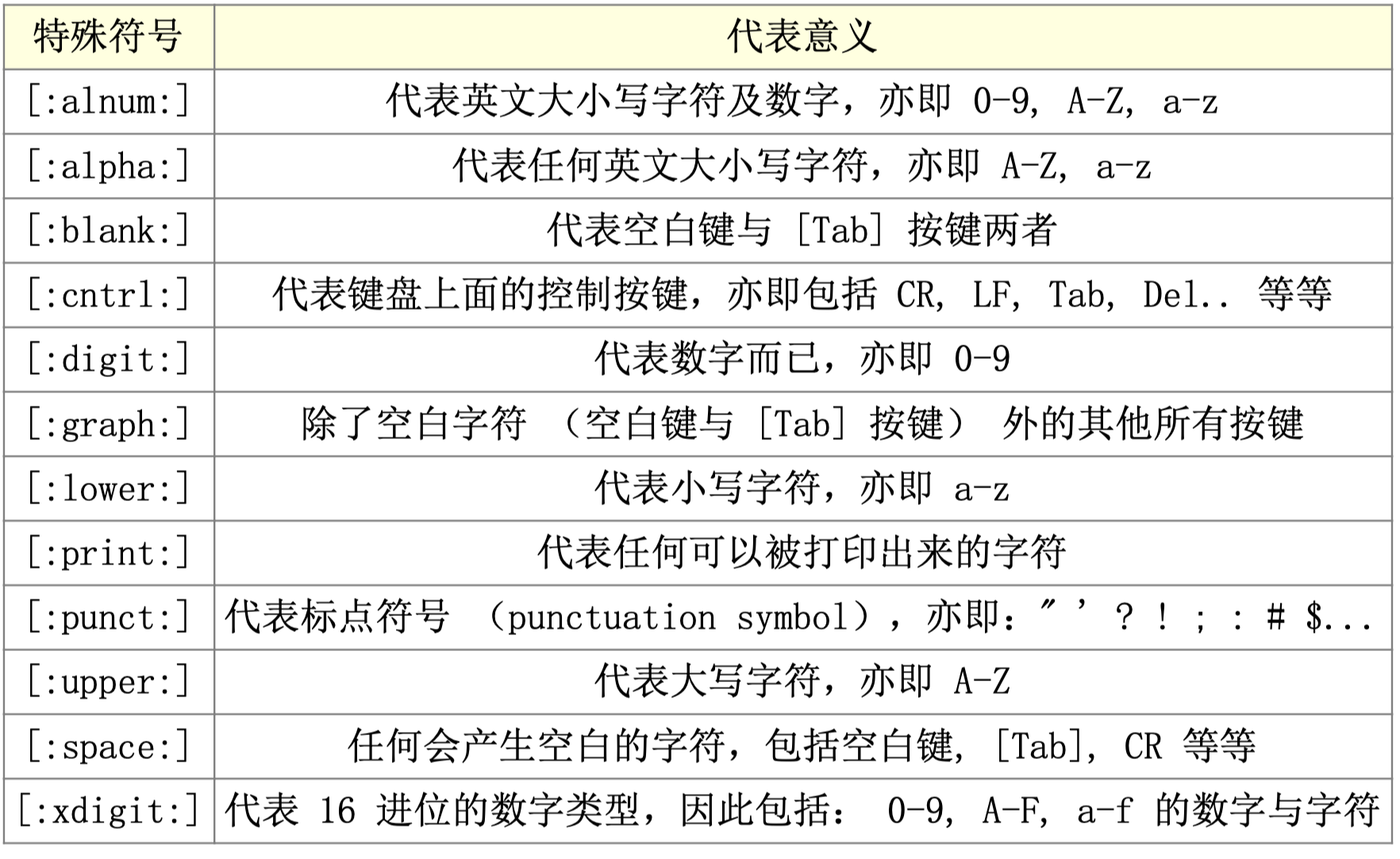
grep的进阶选项 
grep练习:
想要查找test 或者taste两个单字的行
grep -n 't[ae]st' xxx.txt
#[]中不论有几个字符,他都仅代表一个字符而已2.想要找oo,但不想要前面有g
grep -n '[^g]oo' xxx.txt
#[^]反向选择内部的一个字符3.想要找oo,但不想要前面有小写字符
grep -n '[^a-z]oo' xxx.txt
grep -n '[^[:lower:]]oo' xxx.txt
#符号可以配合使用4.想要找有the的,但只出现行^首(尾$)
grep -n '^the' xxx.txt
#只出现在行首ps:^在[]内外的表达是不同的!在内为反向选择,在外为行首的意思
5.找出空白行
grep -n '^$' xxx.txt
#找出空白行
grep -v '^$' xxx
#找出非空白的行,节省打印空间,实用6.*与.
 ps:==*代表的是重复0个或者多个前面的RE字符==
ps:==*代表的是重复0个或者多个前面的RE字符==
7.得到g......g
grep -n 'g.*g' xxx.txt
#秒! 表示中间有0个或者多个的.!!!8.{}符
#找到g....g中间有2-5个o的
grep -n 'o\{2,5\}' xxx.txt
#找到中间有2个以上的o
grep -n 'go*g' xxx.txt
grep -n 'go\{2,\}' xxx.txt总结:

二、sed工具
sed是一个管线命令,可以分析stdin。而且sed还可以将数据进行取代、删除、新增、颉取特定行的功能

练习: 1.列出内容并打印行号,同时删除2-5行
nl /etc/passwd | sed '2,5d'2.承上题,在第二行后(亦即是加在第三行)加上“drink tea?”字样
nl /etc/passwd | sed '2a drink tea'
#如果要在第二行加入,则把a改成i3.承上题,如何新增多行?
#使用/符号,进行加入多行操作
nl /etc/passwd | sed '2a drink tea .....\
drink tea?'输出: 
4.承上题,取代2-5行内容
nl /etc/passwd | sed '2,5c No 2-5 number'5.承上题,仅列出文件内的5-7行
nl /etc/passwd | sed -n '5,7p'
#p:print6.搜索与取代
sed 's/要被取代的字串/新的字串/g'
sed与正则表达式混合练习
7.删除man中的前面注解,只保留有用的行 

sed直接修改文件内容(危险动作) 
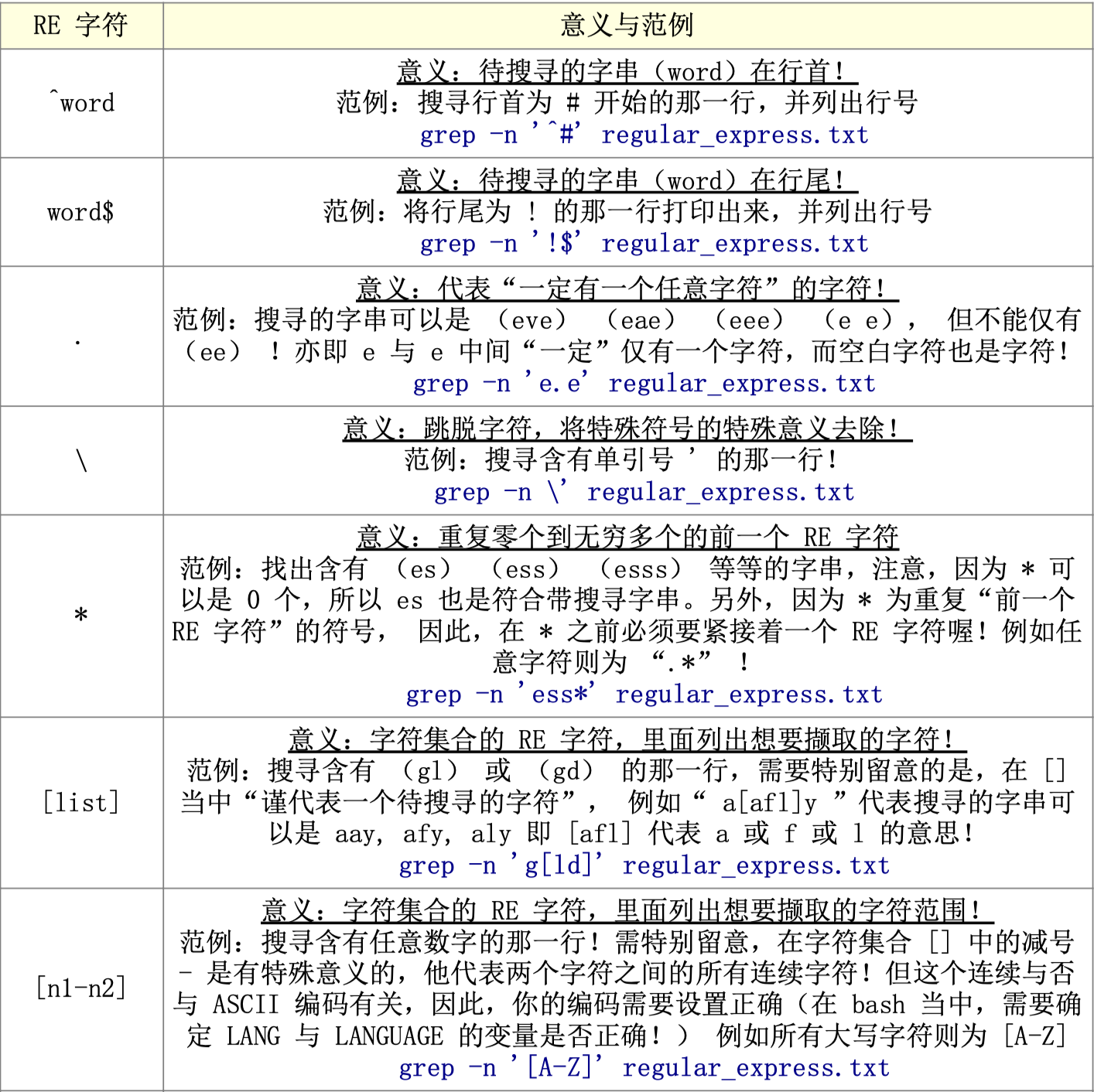
三、延伸正则表达式
延伸正则表达式可以通过群组功能“|”来进行一次搜寻!那个在单引号内的管线意义为“or“
#例如我们去除空白行和行首为#的行列,之前要使用两次管线
grep -v '^$' xxx.txt | grep -v '^#'
#现在可以使用延伸正则表达式
egrep -v '^$|^#' xxx.txt
#egrep == grep -E https://img-1329949402.cos.ap-shanghai.myqcloud.com/20241226065840.png
https://img-1329949402.cos.ap-shanghai.myqcloud.com/20241226065840.png
ps:==!在延伸表达式里不是特殊字符!!! 常见错误:[!a-z]是反向选择? 不对,要‘a-z’==
11.4 文件的格式化与相关处理
11.4.1 格式化打印
printf:
printf '打印格式' 实际内容
printf '%s\t %s\t %s\t %s\t %s\t \n' $ (cat printf.txt)
# %s表示不固定长度字串
# 每组数据中有一个[tab]
printf '%10s %5i %5i %5i %8.2f' $ (cat printf.txt | grep -v Name)
#%8.2f 意思是总长占8个字符,小数点后共两位11.4.2 awk
awk: awk是一个优秀的数据处理工具
相比sed一次处理一行,awk倾向于一次处理一行中的一个字段
awk '条件类型1{动作1} 条件类型2{动作2}...' filename
#例如
last -n 5 | awk '{print $1 "\t" $3}'
#$n代表第n栏数据。如果是$0代表一整列数据
#原格式
dmtsai pts/0 192.168.1.100 Tue Jui 14 17:32 still loggedin
dmtsai pts/0 192.168.1.100 Tue Jui 14 17:32 still loggedin
dmtsai pts/0 192.168.1.100 Tue Jui 14 17:32 still loggedin
dmtsai pts/0 192.168.1.100 Tue Jui 14 17:32 still loggedin
dmtsai pts/0 192.168.1.100 Tue Jui 14 17:32 still loggedin
#输出如下
dmtsai 192.168.1.100
dmtsai 192.168.1.100
dmtsai 192.168.1.100
dmtsai 192.168.1.100
dmtsai 192.168.1.100整个awk的处理流程如下:
读入第一行,并将第一行的数据填入$0, $1...等变量当中
依据条件类型的限制,判断是否需要进行后面的”动作“
做完所有的动作与条件类型
若还有后续的”行“的数据,则重复上面的1-3 的步骤,直到所有的数据都读完为止
awk内置变量:
NF: 每一行($0)拥有的字段总数
NR: 目前awk处理的是”第几行“数据
FS: 目前的分割字符,默认是空白键
#示例
last -n 5 | awk'{print $1 "\t" lines: "NR", columns: "NF"}'
#输出结果
dmtsai lines:1 columns:10
dmtsai lines:1 columns:10
dmtsai lines:1 columns:10
dmtsai lines:1 columns:10
dmtsai lines:1 columns:9awk的逻辑运算字符
cat /etc/passwd | awk 'BEGIN {FS = ":"} $3 < 10 {print $1 "\t" $3}'
#输出
root 0
bin 1
daemon 2
...
awk实现计算
#示例数据如下,假如有一个薪资表为pay.txt
Name 1st 2nd 3th
VBird 23000 24000 25000
DMTsai 21000 20000 23000
Bird2 43000 42000 41000
#计算每个人的总额并且格式化输出
cat pay.txt | \
> awk 'NR == 1 {printf "%10s %10s %10s %10s %10s\n", $1,$2,$3,$4,"Total"}'
> NR>=2 {total = $2 + $3 + $4
> printf "%10s %10d %10d %10d %10.2f\n", $1,$2,$3,$4, total}
11.4.3 文件比对工具
比对ASCII纯文本工具:diff 比对非存文本工具: cmp
diff:主要以行为比对单位
diff [-bBi] from-file to-file
-b: 忽略一行当中,仅有的多个空白的差异
-B: 忽略空白行的差异
-i: 忽略大小写的不同cmp:主要以字节为比对单位
cmp可以用来比对binary file
cmp [-l] file1 file2
-l:将所有的不通电的字节处都列出来。因为cmp默认金辉输出第一个发现的不同点Patch:
diff ➡ 找到差异 ➡ 写入patch文件 ➡ 用patch文件实现更新与回退
#制作,patch文件
diff -Naur passwd.old passwd.new > passwd.patch cat passwd.patch
#patch文件内容
--- passwd.old 2015-07-14 22:37:43.322535054 +0800 <==旧文件的ؑ信息
+++ passwd.new 2015-07-14 22:38:03.010535054 +0800 <==新文件的信息
@@ -1,9 +1,8 @@ <==新旧文件要修改数据的界定范围,
旧文件൘ 1-9 行,
新文件൘ 1-8 行
root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/sbin/nologin daemon:x:2:2:daemon:/sbin:/sbin/nologin
-adm:x:3:4:adm:/var/adm:/sbin/nologin <==左侧文件删除lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
-sync:x:5:0:sync:/sbin:/bin/sync <==左侧文件删䲔
+no six line <==右侧新文件加
#使用patch文件
patch -p0 < passwd.patch
patch -p0 < passwd.patch #更新旧版数据
patching file passwd.old
patch -R -p0 < passwd.patch # 恢复旧文件的内容11.4.4文件打印 pr
