

参考资料
Linux Namespace:https://lwn.net/Articles/531114/
🫛RootFs
rootfs 是Docker 容器在启动时内部进程可见的文件系统,即Docker容器的根目录。rootfs通常包含一个操作系统运行所需的文件系统,例如可能包含经典的类Unix操作系统中的目录系统,如/dev、/proc、/bin、/etc、/lib、/usr、/tmp及运行Docker容器所需的配置文件、工具等。
🥬Linux Namespace
Namespace是 Linux 内核用来隔离内核资源的方式。Linux实现了六种不同类型的命名空间。每个命名空间的用途是将特定的全局系统资源包装在抽象中,使命名空间中的进程看起来它们具有自己的全局资源独立实例。命名空间的总体目标之一是支持容器的实现。
🍈进程命名空间
lsns命令说明
列出系统命名空间
-p、 --task<pid>打印进程命名空间NS:命名空间标识符(索引节点号)
TYPE:命名空间类型
PATH:命名空间的PATH路径
NPROCS:命名空间中的进程数
PID:命名空间中的最小PID
PPID:PID的父级PID
COMMAND:PID的命令行
UID:PID的UID
USER:PID的User
NETNSID:网络子系统使用的命名空间ID
NSFS:nsfs 文件系统挂载点(通常用于网络子系统)
查看元组进程命名空间
1.列出系统所有命名空间
sudo lsns --output-all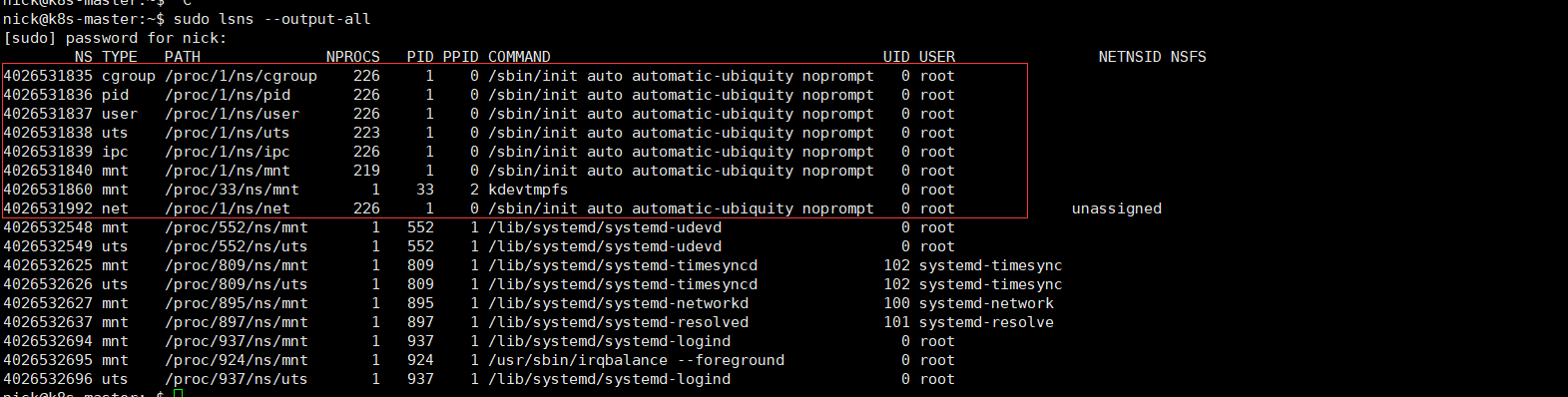
上图红色框内命名空间所属进程ID为1,表示元组进程的命名空间,即系统默认命名空间。进程没有特殊指定需要创建新的命名空间的情况下,命名空间将与父进程保持一致
2.通过文件查看元组进程命名空间
sudo ls -al /proc/1/ns --color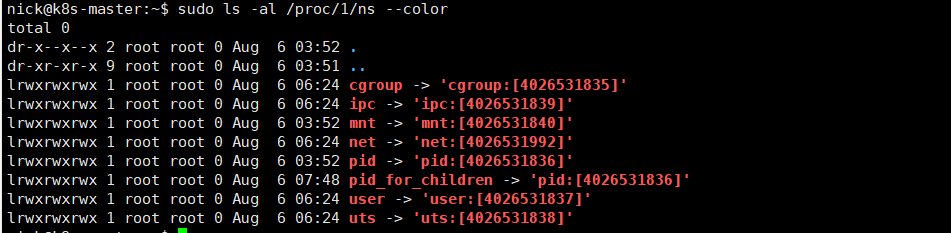
查看当前用户进程命名空间
1.查看当前用户进程命名空间列表
lsns --output-all
2.fork一个新进程,并且不共享父进程命名空间
# 创建新的进程
# 若没有指定-U则需要超级权限
unshare --fork -m -u -i -n -p -U -C sleep 100
# 查看所有命名空间
lsns --output-all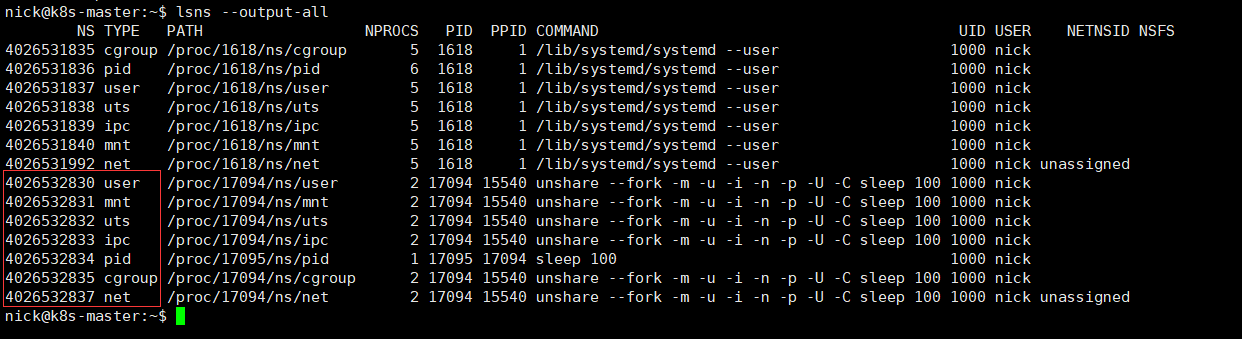
新fork出来的进程,在指定新命名空间后,其命名空间字段的值与系统默认命名空间不一致,说明进程创建了新的命名空间
容器进程命名空间
查看容器进程命名空间列表
1.运行容器,获取进程ID
#启动nginx容器
docker run -d --name mynginx nginx
#获取nginx主进程ID
docker top mynginx
#查看进程命名空间
sudo lsns -p <pid> --output-all2.查看容器进程的命名空间情况

nginx容器默认使用mnt、uts、ipc、pid、net命名空间隔离,而user与cgroup则继承系统默认命名空间。网络命名空间指定了文件系统挂载点
容器进程命名空间的具体体现
1.开启docker user命名空间配置,/etc/docker/daemon.json 文件添加以下选项
//默认生成
"userns-remap":"default"
//或者指定已存在用户和组
"userns-remap":"user:group"2.重启docker服务
sudo systemctl restart docker.service3.宿主机上查看docker容器默认生成的用户配置
cat /etc/subuid
cat /etc/subgid
id <user>/etc/subuid文件:dockremap:165536:65536 表示宿主机使用dockremap用户,容器使用其从属ID,范围从0~65536,与之对应的宿主机ID范围:165536~165536+65536/etc
/subgid文件:针对用户组与/etc/subuid 类似
4.User命名空间: 启动新的nginx容器,查看user命名空间
#运行容器,指定私有cgroups,指定user
dockerrun -d --cgroups private --user oor --name mynginx1 nginx
#查看容器在宿主机上的进程信息,UID显示并不是root
docker top mynginx1
#与容器交互,查看当前用户信息,显示为root,也可通过id查看用户信息
docker exec -it mynginx1 bash
#查看进程命名空间,进程拥有独立的命名空间
sudo lsns -p <pid> --output-all
UTS命名空间:启动新容器,设置hostname与domain
# 运行容器,指定hostname与域名
docker run -d --domainname abc.nick.com --hostname abcdefg --userns host --name
mynginx2 nginx
# 与容器交互,进入交互模式
docker exec -it mynginx2 bash
# 访问hostname 与 domainname
hostname
domainname
# 通过hostname与domainname访问应用
curl http://abcdefg
curl http://abcdefg.abc.nick.com
# 通过文件查看hostname与domainname
cat /proc/sys/kernel/hostname
cat /proc/sys/kernel/domainname\6. mount、PID、Network 命名空间:启动一个工具容器
# 运行工具容器
docker run -dit --name mycurl radial/busyboxplus:curl
# 进入交互模式
docker exec -it mycurl shmount命名空间:容器内部执行mount 与宿主机内执行mount命令对比,即可看出各自拥有不同的mounts。
mounts文件位于:/proc/mounts 和 /proc/{PID}/mounts。mounts文件列说明:
Device mount的设备
Mount Point 挂载点,也就是挂载的路径
File System Type 文件系统类型,如ext4、xfs等
Options 挂载选项,包括读写权限等参数
无用内容,保持内容和/etc/fstab格式一致
无用内容,保持内容和/etc/fstab格式一致
PID明明空间:容器进步进程ID 为1,宿主机内进程ID不为1
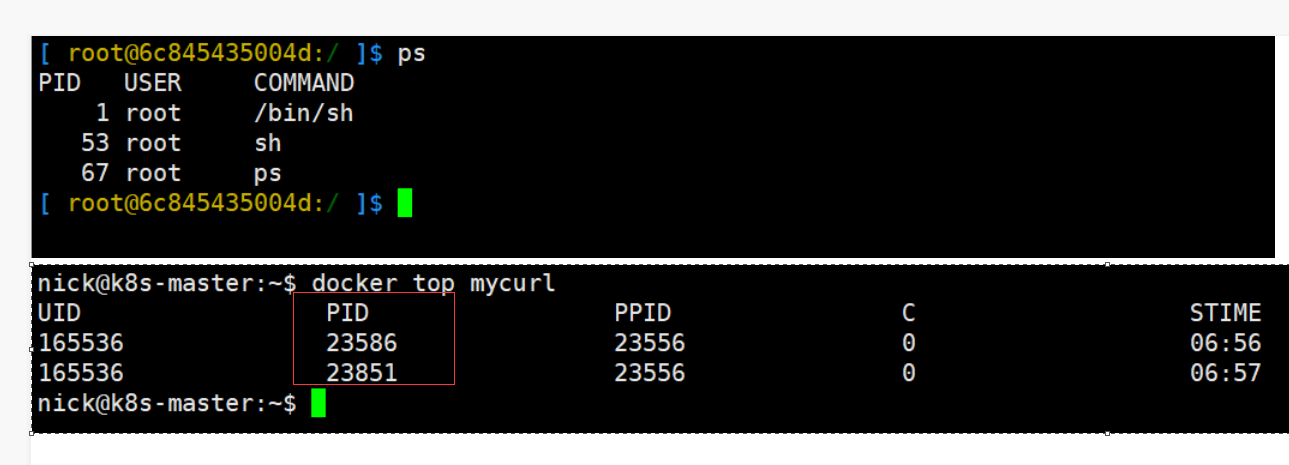
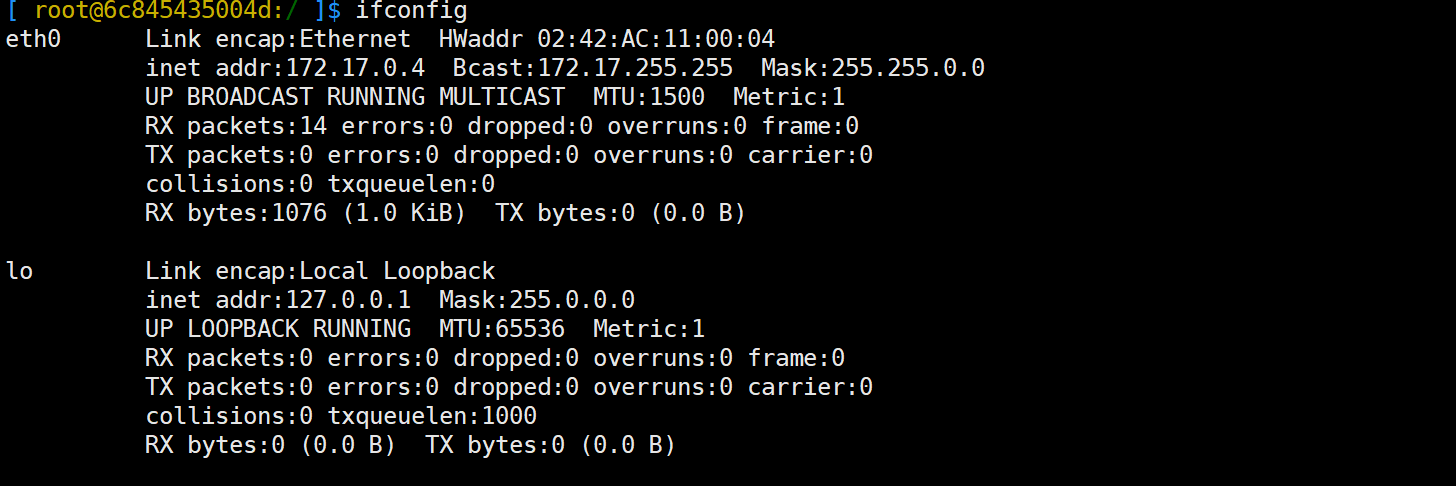
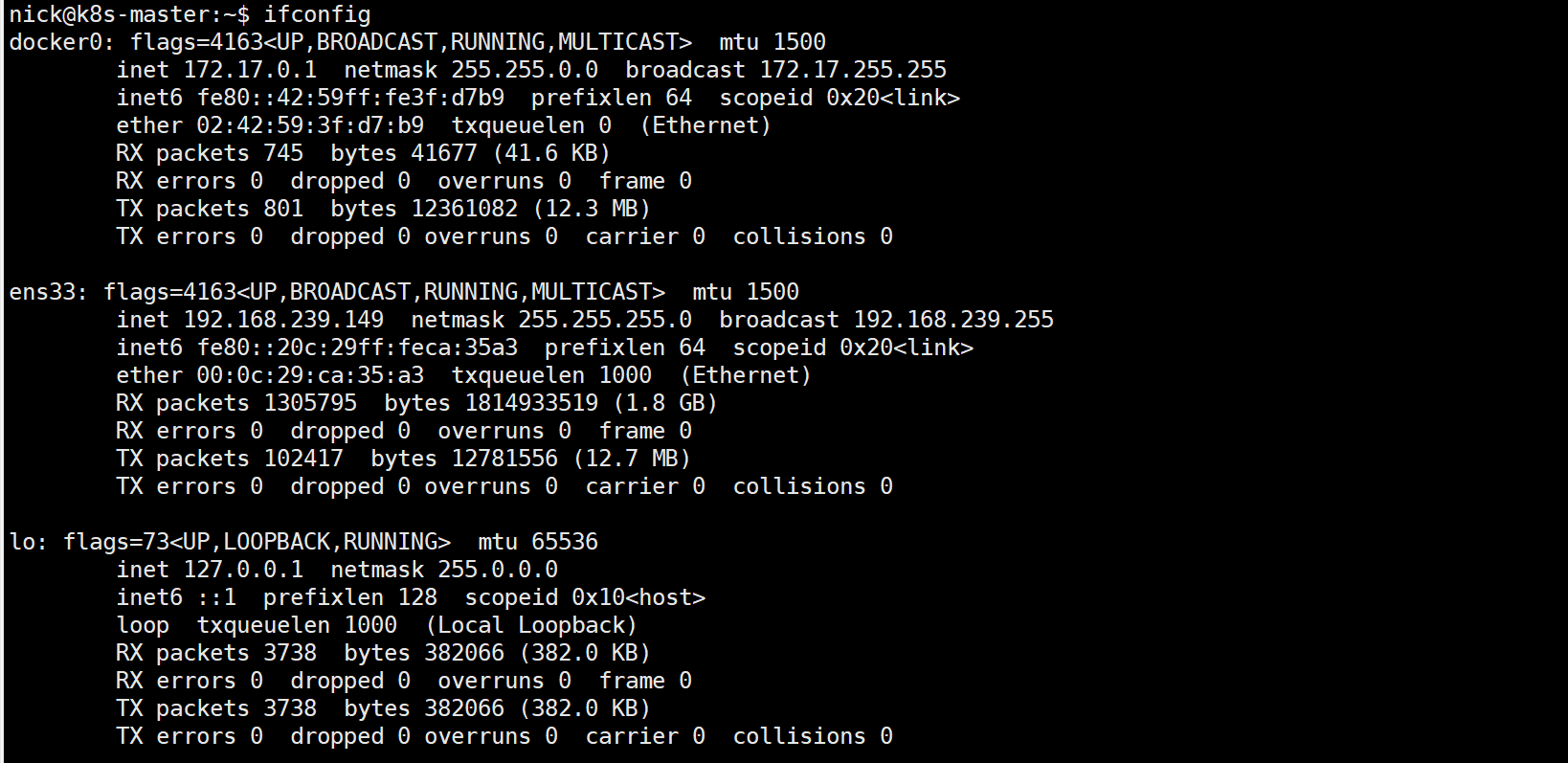
NetWork命名空间:通过ifconfig工具,查看网络信息。容器与宿主机网络完全是两个独立的网络栈
🍊Cgroups(暂时没掌握)
cgroup全称是control groups,被整合在了linux内核当中,把进程(tasks)放到组里面,对组设置权限,对进程进行控制。可以理解为用户和组的概念,用户会继承它所在组的权限
cpu子系统
调度 cgroup 对 CPU 的获取量。可用以下两个调度程序来管理对 CPU 资源的获取:
完全公平调度程序(CFS) — 一个比例分配调度程序,可根据任务优先级 ⁄ 权重或 cgroup 分得的份额,在任务群组(cgroups)间按比例分配 CPU 时间(CPU 带宽)
实时调度程序(RT) — 一个任务调度程序,可对实时任务使用 CPU 的时间进行限定
CFS
cpu.cfs_period_us:此参数可以设定重新分配 cgroup 可用 CPU 资源的时间间隔,单位为微秒,上限1秒,下限1000微秒。即设置单个CPU重新分配周期
cpu.cfs_quota_us:此参数可以设定在某一阶段(由 cpu.cfs_period_us 规定)某个 cgroup 中所有任务可运行的时间总量,单位为微秒。即每个周期时间内,可以使用多长时间的CPU(单个),该值可以大于cfs_period_us的值,表示可以利用多个CPU来满足CPU使用时
cpu.shares:用一个整数来设定cgroup中任务CPU可用时间的相对比例。该参数是对系统所有CPU做分配,不是单个CPU。
cpu.stat:报告 CPU 时间统计 ,
nr_periods : 经过的周期间隔数
nr_throttled : cgroup 中任务被节流的次数(即耗尽所有按配额分得的可用时间后,被禁止运行)
throttled_time : cgroup 中任务被节流的时间总计(以纳秒为单位)
RT
RT 调度程序与 CFS 类似,但只限制实时任务对 CPU 的存取。
cpu.rt_period_us:此参数可以设定在某个时间段中 ,每隔多久,cgroup 对 CPU 资源的存取就要重新分配,单位为微秒(µs,这里以“us”表示),只可用于实时调度任务
cpu.rt_runtime_us:此参数可以指定在某个时间段中, cgroup 中的任务对 CPU 资源的最长连续访问时间,单位为微秒(µs,这里以“us”表示),只可用于实时调度任务
示例
1.一个cgroup使用一个cpu的25%,同时另一个cgroup使用此cpu的75%
echo 250 > /cgroup/cpu/blue/cpu.shares
echo 750 > /cgroup/cpu/red/cpu.shares2.一个cgroup完全使用一个cpu
echo 10000 > /cgroup/cpu/red/cpu.cfs_quota_us
echo 10000 > /cgroup/cpu/red/cpu.cfs_period_us3.一个cgroup使用cpu的10%
echo 10000 > /cgroup/cpu/red/cpu.cfs_quota_us
echo 100000 > /cgroup/cpu/red/cpu.cfs_period_us4.多核系统中,如要让一个cgroup完全使用两个核
echo 200000 > /cgroup/cpu/red/cpu.cfs_quota_us
echo 100000 > /cgroup/cpu/red/cpu.cfs_period_uscpuset子系统
可以为 cgroup 分配独立 CPU 和内存节点1cpuset.cpu_exclusive:包含标签(0 或者 1),它可以指定:其它 cpuset 及其父、子 cpuset 是否可共享该 cpuset 的特定 CPU。默认情况下(0),CPU 不会专门分配给某个 cpuset
cpuset.cpus(强制):设定该 cgroup 任务可以访问的 CPU。这是一个逗号分隔列表,格式为ASCII,小横线("-")代表范围。例如:0-2,16 表示cpu 0、1、2 和 16
cpuset.mem_exclusive:包含标签(0 或者 1),它可以指定:其它 cpuset 是否可共享该 cpuset的特定内存节点。默认情况下(0),内存节点不会专门分配给某个 cpuset 。为某个 cpuset 保留其专用内存节点(1)与使用cpuset.mem_hardwall 参数启用内存 hardwall 功能是一样的
cpuset.mem_hardwall:包含标签(0 或者 1),它可以指定:内存页和缓冲数据的 kernel 分配是否受到 cpuset 特定内存节点的限制。默认情况下 0,页面和缓冲数据在多用户进程间共享。启用 hardwall 时(1)每个任务的用户分配可以保持独立
cpuset.memory_migrate:包含一个标签(0 或者 1),用来指定当 cpuset.mems 的值更改时,是否应该将内存中的页迁移到新节点。默认情况下禁止内存迁移(0)且页就保留在原来分配的节点中,即使此节点不再是 cpuset.mems 指定的节点。如果启用(1),系统会将页迁移到cpuset.mems 指定的新参数的内存节点中,如果可能的话会保留其相对位置。
cpuset.memory_pressure:一份只读文件,包含该 cpuset 进程生成的“内存压力”运行平均。启用cpuset.memory_pressure_enabled 时,该伪文件中的值会自动更新,除非伪文件包含 0 值。
cpuset.memory_pressure_enabled:包含标签(0 或者 1),它可以设定系统是否计算该 cgroup进程生成的“内存压力”。计算出的值会输出到 cpuset.memory_pressure,代表进程试图释放被占用内存的速率,报告值为:每秒尝试回收内存的整数值再乘以 1000。
cpuset.memory_spread_page:包含标签(0 或者 1),它可以设定文件系统缓冲是否应在该cpuset 的内存节点中均匀分布。默认情况下 0,系统不会为这些缓冲平均分配内存页面,缓冲被置于生成缓冲的进程所运行的同一节点中。
cpuset.memory_spread_slab:包含标签(0 或者 1),它可以设定是否在 cpuset 间平均分配用于文件输入 / 输出操作的 kernel 高速缓存板。默认情况下 0,kernel 高速缓存板不被平均分配,高速缓存板被置于生成它们的进程所运行的同一节点中。
cpuset.mems(强制):设定该 cgroup 中任务可以访问的内存节点。这是一个逗号分隔列表,格式为 ASCII,小横线("-")代表范围。例如:0-2,16 表示内存节点 0、1、2 和 16。内存节点:内存被划分为节点,每一个节点关联到一个cpu
cpuset.sched_load_balance:包含标签(0 或者 1),它可以设定 kernel 是否在该 cpuset 的CPU 中平衡负载。默认情况下 1,kernel 将超载 CPU 中的进程移动到负载较低的 CPU 中以便平衡负载。如果父cgroup设置了,子cgroup的设置将没有任何作用
cpuset.sched_relax_domain_level:包含 -1 到一个小正数间的整数,它代表 kernel 应尝试平衡负载的 CPU 宽度范围。如果禁用 cpuset.sched_load_balance,则该值无意义
cpuacct子系统
自动生成报告来显示 cgroup 任务所使用的 CPU 资源,其中包括子群组任务
cpuacct.stat:报告此 cgroup 的所有任务(包括层级中的低端任务)使用的用户和系统 CPU 时间user: 用户模式中任务使用的 CPU 时间system: 系统(kernel)模式中任务使用的 CPU 时间
cpuacct.usage:报告此 cgroup 中所有任务(包括层级中的低端任务)使用 CPU 的总时间(纳秒)
cpuacct.usage_percpu:报告 cgroup 中所有任务(包括层级中的低端任务)在每个 CPU 中使用的 CPU 时间(纳秒)
memory子系统
自动生成 cgroup 任务使用内存资源的报告,并限定这些任务所用内存的大小
memory.failcnt:报告内存达到memory.limit_in_bytes 设定的限制值的次数
2.memory.force_empty:当设定为 0 时,该 cgroup 中任务所用的所有页面内存都将被清空。这个接口只可在 cgroup 没有任务时使用。如果无法清空内存,请在可能的情况下将其移动到父 cgroup中。移除 cgroup 前请使用 memory.force_empty 参数以免将废弃的页面缓存移动到它的父cgroup 中3.memory.limit_in_bytes:设定用户内存(包括文件缓存)的最大用量。如果没有指定单位,则该数值将被解读为字节。但是可以使用后缀代表更大的单位 —— k 或者 K 代表千字节,m 或者 M 代表兆字节 ,g 或者 G 代表千兆字节。在 memory.limit_in_bytes 中写入 -1 可以移除全部已有限制。
memory.max_usage_in_bytes:报告 cgroup 中进程所用的最大内存量(以字节为单位)
move_charge_at_immigrate:当将一个task移动到另一个cgroup中时,此task的内存页可能会被重新统计到新的cgroup中,这取决于是否设置move_charge_at_immigrate
numa_stat: 每个numa节点的内存使用数量
memory.oom_control:设置or查看内存超限控制信息(OOM killer)
memory.pressure_level:设置内存压力通知
memory.soft_limit_in_bytes:内存软限制
memory.stat:报告大范围内存统计
memory.swappiness:将 kernel 倾向设定为换出该 cgroup 中任务所使用的进程内存,而不是从页高速缓冲中再生页面
memory.usage_in_bytes:报告 cgroup 中进程当前所用的内存总量(以字节为单位)
memory.use_hierarchy:包含标签(0 或者 1),它可以设定是否将内存用量计入 cgroup 层级的吞吐量中。如果启用(1),内存子系统会从超过其内存限制的子进程中再生内存。默认情况下(0),子系统不从任务的子进程中再生内存
内核内存:专用于Linux内核系统服务使用,是不可swap的
memory.kmem.failcnt:报告内核内存达到 memory.kmem.limit_in_bytes 设定的限制值的次数
memory.kmem.limit_in_bytes:设定内核内存(包括文件缓存)的最大用量。如果没有指定单位,则该数值将被解读为字节
memory.kmem.max_usage_in_bytes:报告 cgroup 中进程所用的最大内核内存量(以字节为单位)
memory.kmem.slabinfo:查看内核内存分配情况
memory.kmem.usage_in_bytes:报告 cgroup 中进程当前所用的内核内存总量(以字节为单位)
memory.kmem.tcp.failcnt:报告tcp缓存内存达到memory.kmem.tcp.limit_in_bytes设定限制值的次数
memory.kmem.tcp.limit_in_bytes:设置或查看TCP缓冲区的内存使用限制
memory.kmem.tcp.max_usage_in_bytes:报告cgroup中进程所用的最大tcp缓存内存量
memory.kmem.tcp.usage_in_bytes:报告cgroup中进程当前所用TCP缓冲区的内存使用量
示例
1.cgroup中任务可用的内存量设定为100MB
echo 104857600 > memory.limit_in_bytesblkio子系统
控制并监控 cgroup 中的任务对块设备 I/O 的存取。对一些伪文件写入值可以限制存取次数或带宽,从伪文件中读取值可以获得关于 I/O 操作的信息。
blkio.reset_stats:此参数用于重设其它伪文件记录的统计数据。请在此文件中写入整数来为cgroup 重设统计数据
blkio.throttle.io_service_bytes:此参数用于报告 cgroup 传送到具体设备或者由具体设备中传送出的字节数。
blkio.throttle.io_serviced:此参数用于报告 cgroup 根据节流方式在具体设备中执行的 I/O 操作数。
blkio.throttle.read_bps_device:此参数用于设定设备执行“读”操作字节的上限。“读”的操作率以每秒的字节数来限定。
blkio.throttle.read_iops_device:此参数用于设定设备执行“读”操作次数的上限。“读”的操作率以每秒的操作次数来表示。
blkio.throttle.write_bps_device:此参数用于设定设备执行“写”操作次数的上限。“写”的操作率用“字节/秒”来表示echo 104857600 > memory.limit_in_bytes
\7. blkio.throttle.write_iops_device:此参数用于设定设备执行 “写” 操作次数的上限。“写”的操作率以每秒的操作次数来表示。
devices子系统
允许或者拒绝 cgroup 任务存取设备
devices.allow:指定 cgroup 任务可访问的设备
devices.deny:指定 cgroup 任务无权访问的设备
devices.list:报告 cgroup 任务对其访问受限的设备
freezer子系统
暂停或者恢复 cgroup 中的任务
freezer.state:
FROZEN: cgroup 中的任务已被暂停
FREEZING:系统正在暂停 cgroup 中的任务
THAWED: cgroup 中的任务已恢复
net_cls子系统
使用等级识别符(classid)标记网络数据包,这让 Linux 流量管控器(tc)可以识别从特定 cgroup 中生成的数据包。可配置流量管控器,让其为不同 cgroup 中的数据包设定不同的优先级
net_cls.classid: 包含表示流量控制 handle 的单一数值。从 net_cls.classid 文件中读取的 classid值是十进制格式,但写入该文件的值则为十六进制格式
net_prio子系统
可以为各个 cgroup 中的应用程序动态配置每个网络接口的流量优先级。网络优先级是一个分配给网络流量的数值,可在系统内部和网络设备间使用。网络优先级用来区分发送、排队以及丢失的数据包
net_prio.prioidx:只读文件。它包含一个特有整数值,kernel 使用该整数值作为这个 cgroup 的内部代表。
net_prio.ifpriomap:包含优先级图谱,这些优先级被分配给源于此群组进程的流量以及通过不同接口离开系统的流量
perf_event
允许使用perf工具来监控cgroup
hugetlb
允许使用大篇幅的虚拟内存页,并且给这些内存页强制设定可用资源量