

定义
设计模式是什么:解决特定环境下,重复出现的,特定问题的解决方案(解决问题的固定套路)
场景
具体需求既有稳定点,又有变化点,希望修改少量的代码,就可以适应需求的变化
全是稳定点,变化点都不适合用设计模式
比喻:整洁的房间,好动的猫,如何保证房间的整洁?把猫关进笼子里(让代码在有限范围内变化)
基础
面向对象:
1.封装:隐藏实现细节,实现模块化
2.继承:无需修改原有类,实现对功能的拓展
3.多态:静态多态:函数重载。动态多态:继承中虚函数重写
实现多态:
1.静态多态
静态绑定(早绑定):没有虚函数重写,根据用户所传递实参类型就确定了具体调用哪个方法,如:函数重载,函数模板
2.动态多态
动态绑定(晚绑定):有虚函数重写,即在编译时,不能确定方法的行为,需要等到程序运行时,才能够确定具体调用那个类的方法
如下代码:
原则
依赖倒置
依赖倒转原则: 依赖倒转原则(Dependency Inversion Principle, DIP):抽象不应该依赖于细节,细节应 当依赖于抽象。换言之,要针对接口编程,而不是针对实现编程。
开闭
对拓展开放,对修改关闭(针对封装、多态)即软件实体应尽量在不修改原有代码的情况下进行扩展。
单一职责
封装:只实现一个功能
里氏替换
所有引用基类 (父类)的地方必须能透明地使用其子类的对象。因此在程序中尽量使用基类类型来对对象进行定义,而在运行时再确定其子类类型,用 子类对象来替换父类对象。
多态:子类虚函数的覆写一定要覆盖父类的职责
接口隔离
接口隔离原则(Interface Segregation Principle, ISP):使用多个专门的接口,而不使用单一 的总接口,即客户端不应该依赖那些它不需要的接口。
应当为客户端提供尽可能小的单独的接口, 而不要提供大的总接口。
最小知道
一个软件实体应当尽可能少地与其他实体发生相互作用。可降低系统的耦合度,使类与类之间保持松散的耦合关系。
合成复用
组合优于继承
合成复用原则又称为组合/聚合复用原则(Composition/Aggregate Reuse Principle, CARP),其定 义如下:组合优于继承(Composite Reuse Principle, CRP):尽量使用对象组合,而不是继承来达到复用的目的。
合成复用原则就是在一个新的对象里通过关联关系(包括组合关系和聚合关系)来使用一些 已有的对象,使之成为新对象的一部分;新对象通过委派调用已有对象的方法达到复用功能 的目的。简言之:复用时要尽量使用组合/聚合关系(关联关系),少用继承。
目前对设计模式的理解要求
需要知道如何根据项目已用的设计模式拓展项目功能
学习步骤
解决什么问题?(稳定点、变化点)
代码结构是如何
符合哪些设计原则
如何拓展代码
典型应用
模式1:模板方法
模板方法模式 (Template Method)应用场景包括但不限于:
在算法框架固定,但具体步骤有所差异的情形下,如各种排序算法的框架。
当有许多共享相同的方法,但是有小部分需要各自实现的场合。
当需要控制子类扩展的点时。
1.基类有骨架流程接口
定义了一个或多个抽象操作,以及一个或多个非抽象的操作(即模板方法)。这些非抽象操作通常会调用抽象操作。
class Game
{
public:
void play();
protected:
virtual void initialize() = 0;
virtual void startPlay() = 0;
virtual void endPlay() = 0;
};2.对子类开放子流程并且为虚函数
具体子类(Concrete Subclass):实现抽象类中的抽象操作,从而提供了抽象操作的具体实现。
class Chess : public Game
{
protected:
void initialize();
void startPlay();
void endPlay();
};
3.模板方法实现方法:用基类指针指向子类,动态多态
Game* game = new Chess();
game->play();
delete game;
std::cout << std::endl;
game = new Monopoly();
game->play();
delete game;
模板方法模式 (Template Method)的优点
代码复用:通过将不变部分的代码移至父类,子类只需要实现变化的部分,这提高了代码复用。
扩展性好:新增具体类时,不需要改变抽象类和其他具体类的代码,保证了代码的可维护性和扩展性。
引入模板方法可以使子类的实现更加清晰,可维护性也更好。
实现了反向控制(依赖倒置),高层模块对低层模块的控制。
模板方法模式 (Template Method)的缺点 每一个不同的实现都需要一个子类来实现,这可能会导致系统中类的数目增加,增加了系统的复杂性。
父类中的抽象方法由子类实现,子类的执行结果会影响到父类的结果,也就是父类部分对子类产生的依赖性。
模式2:观察者模式
观察者模式(Observer Pattern)是一种常用的设计模式,属于行为型模式。它定义了一种一对多的依赖关系,使得当一个对象(主题)状态发生变化时,所有依赖于它的对象(观察者)都会得到通知并自动更新。
使用场景:
当对象间存在一对多关系时,则使用观察者模式(observer pattern)。比如,当一个对象被修改时,则会自动通知发依赖它的对象。观察者模式属于行为型模式。
不用观察者模式时:接口不稳定,每次添加终端就需要修改
使用观察者模式:
让稳定点稳定,抽象
让变化点变化,扩展
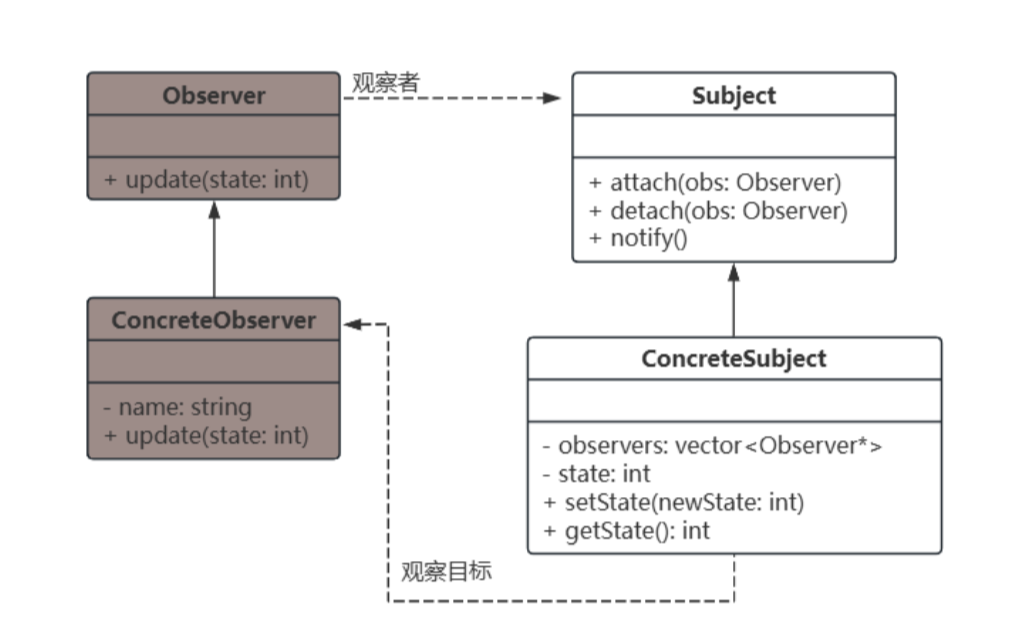
例一:工作流程 观察者注册到主题:在主函数中,使用 attach 方法将观察者注册到主题。 主题的状态发生变化:调用 setState 方法改变主题的状态。 主题调用通知方法:在 setState 方法中,调用 notify 方法通知所有注册的观察者。 观察者接收到通知后,更新自身状态:每个观察者实现 update 方法,接收到通知后更新自身状态并输出。
第一步:定义观察者接口 首先,定义一个观察者接口,所有观察者都需要实现这个接口。
// 观察者接口
class Observer {
public:
virtual void update(int state) = 0; // 更新接口
};第二步:定义主题接口 接下来,定义一个主题接口,主题需要维护观察者列表,并提供添加、删除观察者的方法。
第二步:定义主题接口 接下来,定义一个主题接口,主题需要维护观察者列表,并提供添加、删除观察者的方法。
// 主题接口
class Subject {
public:
virtual void attach(Observer* observer) = 0; // 添加观察者
virtual void detach(Observer* observer) = 0; // 移除观察者
virtual void notify() = 0; // 通知观察者
};第三步:实现具体主题 实现一个具体主题类,维护观察者列表和状态,并在状态变化时通知观察者。
#include <iostream>
#include <vector>
#include <algorithm> // 用于 std::remove
// 具体主题
class ConcreteSubject : public Subject {
private:
std::vector<Observer*> observers; // 观察者列表
int state; // 主题的状态
public:
void attach(Observer* observer) override {
observers.push_back(observer); // 添加观察者
}
void detach(Observer* observer) override {
observers.erase(std::remove(observers.begin(), observers.end(), observer), observers.end()); // 移除观察者
}
void notify() override {
for (Observer* observer : observers) {
observer->update(state); // 通知所有观察者
}
}
void setState(int newState) {
state = newState; // 更新状态
notify(); // 状态变化时通知观察者
}
int getState() const {
return state; // 获取当前状态
}
};第四步:实现具体观察者 实现观察者类,更新自身状态以反映主题的变化。
// 具体观察者
class ConcreteObserver : public Observer {
private:
std::string name; // 观察者名称
int observedState; // 观察者的状态
public:
ConcreteObserver(const std::string& name) : name(name) {}
void update(int state) override {
observedState = state; // 更新观察者的状态
std::cout << "Observer " << name << " updated with state: " << observedState << std::endl;
}
};第五步:主函数 在主函数中,创建主题和观察者对象,注册观察者,并演示状态变化。
// 主函数
int main() {
ConcreteSubject subject; // 创建具体主题
ConcreteObserver observer1("Observer 1"); // 创建观察者1
ConcreteObserver observer2("Observer 2"); // 创建观察者2
subject.attach(&observer1); // 注册观察者1
subject.attach(&observer2); // 注册观察者2
subject.setState(1); // 状态变化,通知所有观察者
subject.setState(2); // 状态变化,通知所有观察者
return 0;
}UML
应用实例:MVC
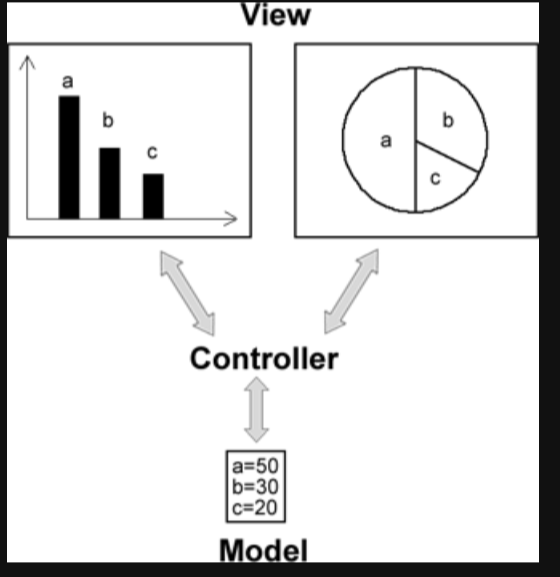
观察者模式与MVC 在当前流行的MVC(Model-View-Controller)架构中也应用了观察者模式,MVC是一种架构模式,它包含了3个角色,即模型(Model),视图(View)和控制器(Controller)。其中,模型可对应于观察者模式中的观察目标,而视图对应于观察者,控制器可充当两者之间的中介者。当模型层的数据发生改变时,视图层将自动改变其显示内容。MVC的结构图如下:
模式3:策略模式
引入"策略“设计模式的定义:定义一些列算法类(策略类),将每个算法封装起来,让他们可以互相替换。换句话说,策略模式通常把一系列算法封装到一系列具体策略类中作为抽象策略类的字类,然后根据实际需要适用这些字类。
稳定点:(抽象)
未来增加什么算法,promotion都很稳定不需要修改,只和传参有关
之前的attach,detach也算依赖注入,通过接口来连接两个类
变化点:通过继承基类,覆写虚函数实现(拓展)
主要组成部分
策略接口 (Strategy):定义一个统一的接口,声明所有支持的算法(策略)的方法。客户端通过这个接口调用具体策略。
具体策略类 (Concrete Strategy):实现策略接口,定义具体的算法或行为。每个具体策略类实现不同的算法。
上下文类 (Context):持有对策略接口的引用,负责调用具体策略的方法。上下文类可以在运行时动态地切换策略。
案例:逐步重构并引入策略模式 假设我们需要实现不同的排序算法(如冒泡排序和快速排序)。最初的实现可能是重复的代码。逐步重构的过程如下:
第一步:初始实现 为每种排序算法编写独立的处理逻辑:
#include <iostream>
#include <vector>
void bubbleSort(std::vector<int>& arr) {
for (size_t i = 0; i < arr.size() - 1; ++i) {
for (size_t j = 0; j < arr.size() - i - 1; ++j) {
if (arr[j] > arr[j + 1]) {
std::swap(arr[j], arr[j + 1]);
}
}
}
}
void quickSort(std::vector<int>& arr, int low, int high) {
if (low < high) {
int pivot = arr[high];
int i = low - 1;
for (int j = low; j < high; ++j) {
if (arr[j] < pivot) {
++i;
std::swap(arr[i], arr[j]);
}
}
std::swap(arr[i + 1], arr[high]);
quickSort(arr, low, i);
quickSort(arr, i + 2, high);
}
}
int main() {
std::vector<int> data = {5, 3, 8, 6, 2};
bubbleSort(data);
// 或者使用 quickSort(data, 0, data.size() - 1);
return 0;
}第二步:提取共性并实现策略接口 识别出排序的共性步骤,并创建一个策略接口 SortStrategy,定义排序方法:
class SortStrategy {
public:
virtual void sort(std::vector<int>& arr) = 0; // 策略接口
};第三步:实现具体策略类 为每种排序算法实现具体策略类,重写排序方法:
class BubbleSort : public SortStrategy {
public:
void sort(std::vector<int>& arr) override {
for (size_t i = 0; i < arr.size() - 1; ++i) {
for (size_t j = 0; j < arr.size() - i - 1; ++j) {
if (arr[j] > arr[j + 1]) {
std::swap(arr[j], arr[j + 1]);
}
}
}
}
};
class QuickSort : public SortStrategy {
public:
void sort(std::vector<int>& arr) override {
quickSort(arr, 0, arr.size() - 1);
}
private:
void quickSort(std::vector<int>& arr, int low, int high) {
if (low < high) {
int pivot = arr[high];
int i = low - 1;
for (int j = low; j < high; ++j) {
if (arr[j] < pivot) {
++i;
std::swap(arr[i], arr[j]);
}
}
std::swap(arr[i + 1], arr[high]);
quickSort(arr, low, i);
quickSort(arr, i + 2, high);
}
}
};第四步:实现上下文类 创建一个上下文类 Sorter,用于使用策略:
class Sorter {
private:
SortStrategy* strategy;
public:
Sorter(SortStrategy* strategy) : strategy(strategy) {}
void setStrategy(SortStrategy* strategy) {
this->strategy = strategy;
}
void sort(std::vector<int>& arr) {
strategy->sort(arr);
}
};策略模式 UML 图

策略模式的 UML 图解析 上下文类 (Context):
Sorter 类:它是上下文类,负责使用策略并持有策略的引用。Sorter 类通过 setStrategy 方法设置具体的排序策略,并通过 sort 方法调用该策略进行排序。 抽象策略类 (Strategy):
SortStrategy 类:这是策略接口,定义了一个公共方法 sort,该方法由具体策略类实现。它确保所有具体策略类都有一致的接口。 具体策略类 (Concrete Strategy):
BubbleSort 类:实现了 SortStrategy 接口,提供了冒泡排序的具体实现。 QuickSort 类:实现了 SortStrategy 接口,提供了快速排序的具体实现。
模式4:单例模式
单例模式:保证一个类只有一个实例,并提供一个该实例的全局访问点 实现方式:构造和拷贝构造设为私有,总共介绍四个版本,推荐使用最后一个。版本1、2、3、4全都是懒汉式的写法。
版本1:线程非安全版本 在多线程情况下可能会同时创建出多个对象,比如,现在有线程A和线程B,线程A进入到16行时, 线程B进入17行,会容易new出多个实例。

版本2:线程安全,但锁的代价过高 在GetInstance()中使用局部变量锁, 保证同一时刻只有一个线程访问30-33行。 读变量没必要加锁,尤其是在高并发的情况下,代价还是挺高的。
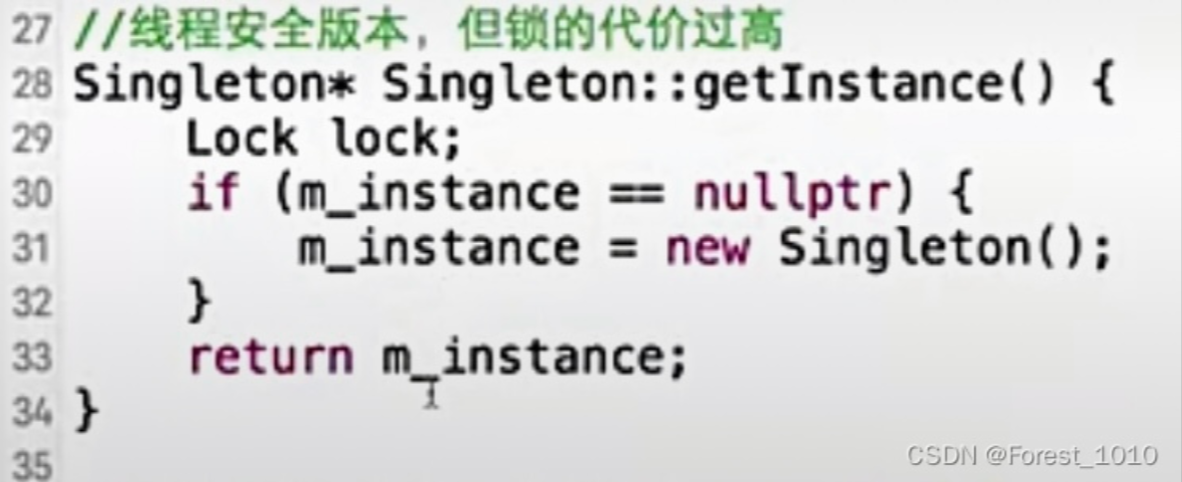
版本3:双检查锁,但由于内存读写reorder(重新排序)不安全(导致双检查锁的失效) 锁前检查,避免都是读取操作时锁代价过高的问题 锁后检查,避免两个线程同时进入,从而new了两个实例

因为编译器优化,指令的执行顺序可能reorder(CPU执行指令的层次,而且线程是在指令层次抢时间片的) ,可能变成这样:分配内存->赋值->调用构造(理想应该是:分配内存->调用构造->赋值) 假设在reorder的情况下:线程1走到赋值,但还没调用构造的阶段,而线程2进来判断m_instance,此时它已经被复制 所以不为空,这时候线程2就直接返回m_instance,但事实上它还没构造出来……这就尴尬了,实际上因为它没有构造,肯定是不能用的。 总之,就是双检查锁 它欺骗了线程2……
怎么解决这个问题呢? Java 和c sharp 添加了一个关键字:volatile 这样,编译时在编译的时候就知道,这个变量的整个赋值过程不能reorder,需要按照常规的流程走。
C++11之后 跨平台实现了volatile 还是挺复杂的哈……
前3个版本均来自侯捷老师的视频,可以去观看一下,讲的灰常简单易懂
版本4:局部静态变量实现单例模式,线程安全(推荐使用)
class Singleton{
public:
~Singleton();
static Singleton& getInstance()
{
static Singleton instance;
return instance;
}
private:
Singleton();
};原因是C++ 11标准中新增了一个特性叫Magic Static:如果变量在初始化时,并发线程同时进入到static声明语句,并发线程会阻塞等待初始化结束。 这样可以保证在获取静态局部变量的时候一定是初始化过的,所以具有线程安全性,同时也避免了new对象时指令重排序造成对象初始化不完全的现象。并且相比较与使用智能指针以及mutex来保证线程安全和内存安全来说,这样做能够提升效率。
模式5:工厂模式
简单工厂
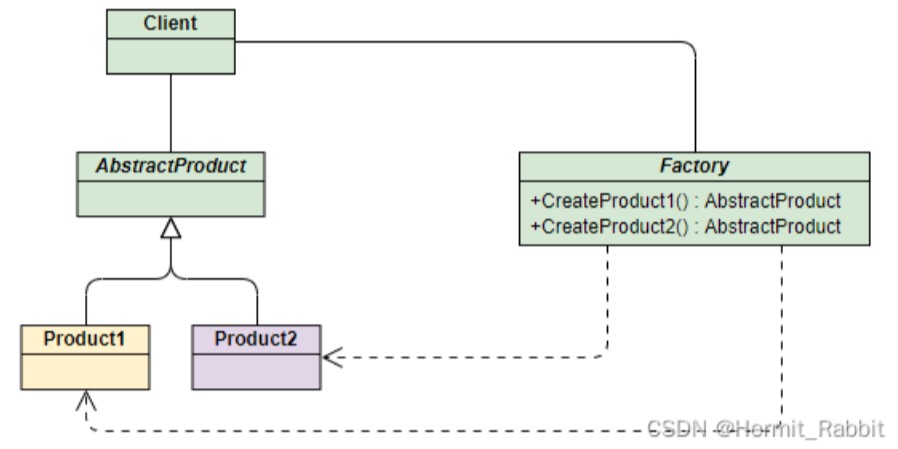
结构组成:
工厂类(ShoesFactory):工厂模式的核心类,会定义一个用于创建指定的具体实例对象的接口。
抽象产品类(Shoes):是具体产品类的继承的父类或实现的接口。
具体产品类(NiKeShoes\AdidasShoes\LiNingShoes):工厂类所创建的对象就是此具体产品实例。
优点与不足:
优点: 结构简单,管理方式简单
缺点: 扩展性非常差,新增产品的时候,需要去修改工厂类。
案例:
抽象产品类,用于存放一类特征相似的实现,并用于定义具体产品类
// 鞋子抽象类
class Shoes
{
public:
virtual ~Shoes() {}
virtual void Show() = 0;
};
// 耐克鞋子
class NiKeShoes : public Shoes
{
public:
void Show()
{
std::cout << "我是耐克球鞋,我的广告语:Just do it" << std::endl;
}
};
// 阿迪达斯鞋子
class AdidasShoes : public Shoes
{
public:
void Show()
{
std::cout << "我是阿迪达斯球鞋,我的广告语:Impossible is nothing" << std::endl;
}
};
工厂类用于统计所有的特征,可以根据enum类型创建具体的产品对象。
enum SHOES_TYPE
{
NIKE,
ADIDAS
};
// 总鞋厂
class ShoesFactory
{
public:
// 根据鞋子类型创建对应的鞋子对象
Shoes *CreateShoes(SHOES_TYPE type)
{
switch (type)
{
case NIKE:
return new NiKeShoes();
break;
case ADIDAS:
return new AdidasShoes();
break;
default:
return NULL;
break;
}
}
};
主函数,先是构造了工厂对象,后创建指定类型的具体产品对象,并实现内部的操作。
int main()
{
ShoesFactory shoesFactory;
// 从鞋工厂对象创建耐克鞋对象
Shoes *pNikeShoes = shoesFactory.CreateShoes(NIKE);
if (pNikeShoes != NULL)
{
// 耐克球鞋广告喊起
pNikeShoes->Show();
// 释放资源
delete pNikeShoes;
pNikeShoes = NULL;
}
// 从鞋工厂对象创建阿迪达斯鞋对象
Shoes *pAdidasShoes = shoesFactory.CreateShoes(ADIDAS)
if (pAdidasShoes != NULL)
{
// 阿里达斯球鞋广告喊起
pAdidasShoes->Show();
// 释放资源
delete pLiNingShoes;
pAdidasShoes = NULL;
}
return 0;
}
工厂方法
和简单工厂模式中工厂负责生产所有产品相比,工厂方法模式将生成具体产品的任务分发给具体的产品工厂,其UML类图如下:
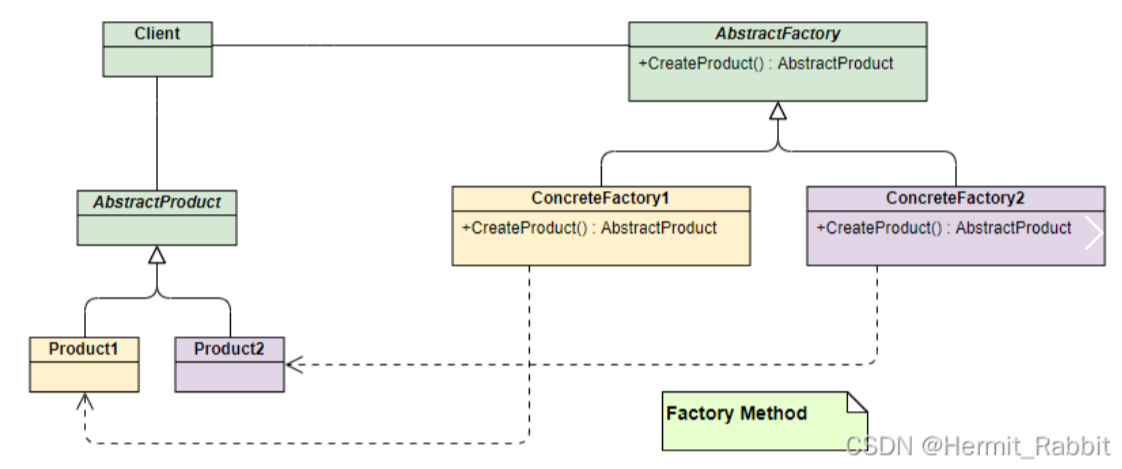
基类工厂提供虚函数功能接口,子类工厂覆写然后实现
结构组成:
抽象工厂类厂(ShoesFactory):工厂方法模式的核心类,提供创建具体产品的接口,由具体工厂类实现。
具体工厂类(NiKeProducer\AdidasProducer\LiNingProducer):继承于抽象工厂,实现创建对应具体产品对象的方式。
抽象产品类(Shoes):它是具体产品继承的父类(基类)。
具体产品类(NiKeShoes\AdidasShoes\LiNingShoes):具体工厂所创建的对象,就是此类。
优点与不足: 优点: 工厂方法模式抽象出了工厂类,并把具体产品对象的创建放到具体工厂类实现。实现了一个工厂生产一类产品,不需要修改工厂类,只需要增加新的具体工厂类即可。
缺点: 每新增一个产品,就需要增加一个对应的产品的具体工厂类。相比简单工厂模式而言,工厂方法模式需要更多的类定义。
案例:
抽象工厂类,提供了创建具体工厂类的纯虚函数,并通过具体工厂类来返回具体产品类
// 总鞋厂
class ShoesFactory
{
public:
virtual Shoes *CreateShoes() = 0;
virtual ~ShoesFactory() {}
};
// 耐克生产者/生产链
class NiKeProducer : public ShoesFactory
{
public:
Shoes *CreateShoes()
{
return new NiKeShoes();
}
};
// 阿迪达斯生产者/生产链
class AdidasProducer : public ShoesFactory
{
public:
Shoes *CreateShoes()
{
return new AdidasShoes();
}
};
抽象产品类同上
//同上主函数函数针对每种类型的具体产品,构造了每种具体产品的具体工厂,再由每个具体工厂生产出对应的产品。
int main()
{
// ================ 生产耐克流程 ==================== //
// 鞋厂开设耐克生产线
ShoesFactory *niKeProducer = new NiKeProducer();
// 耐克生产线产出球鞋
Shoes *nikeShoes = niKeProducer->CreateShoes();
// 耐克球鞋广告喊起
nikeShoes->Show();
// 释放资源
delete nikeShoes;
delete niKeProducer;
// ================ 生产阿迪达斯流程 ==================== //
// 鞋厂开设阿迪达斯生产者
ShoesFactory *adidasProducer = new AdidasProducer();
// 阿迪达斯生产线产出球鞋
Shoes *adidasShoes = adidasProducer->CreateShoes();
// 阿迪达斯球鞋广喊起
adidasShoes->Show();
// 释放资源
delete adidasShoes;
delete adidasProducer;
return 0;
}
抽象工厂
上面两种模式不管工厂怎么拆分抽象,都只是针对一类产品,如果需要多种产品,那就需要使用抽象工厂模式。抽象工厂模式通过在AbstarctFactory中增加创建产品的接口,并在具体子工厂中实现新加产品的创建,当然前提是子工厂支持生产该产品。否则继承的这个接口可以什么也不干。
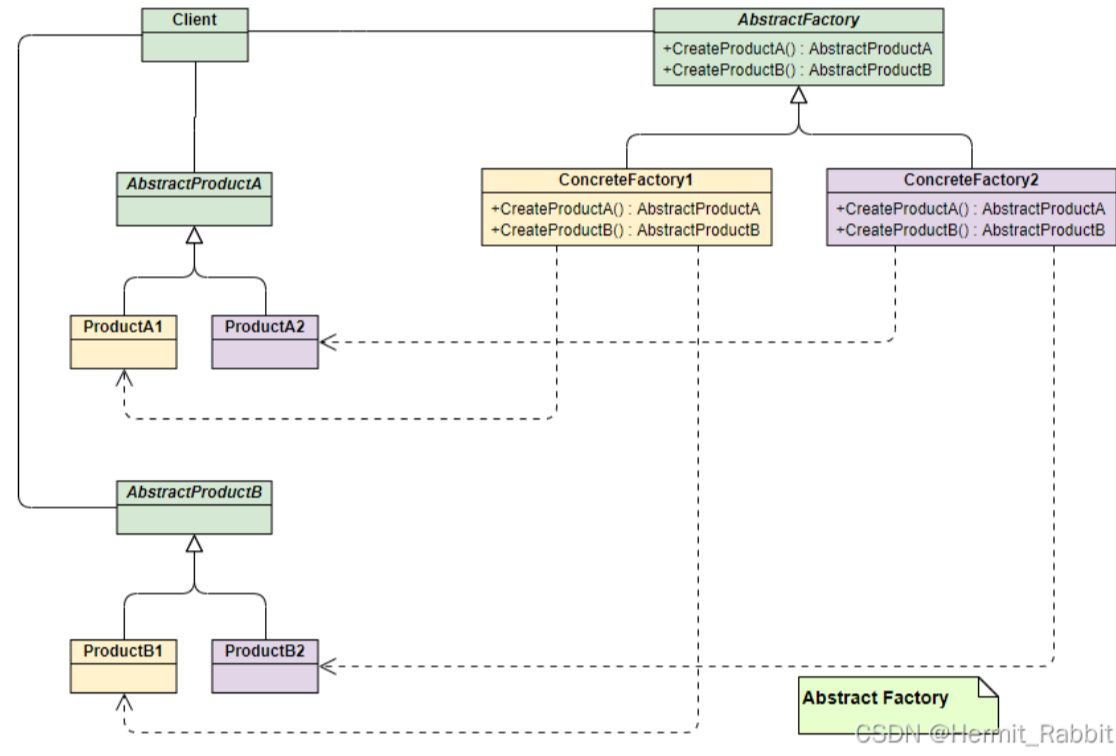
结构组成(和工厂方法模式一样):
抽象工厂类厂(ShoesFactory):工厂方法模式的核心类,提供创建具体产品的接口,由具体工厂类实现。
具体工厂类(NiKeProducer):继承于抽象工厂,实现创建对应具体产品对象的方式。
抽象产品类(Shoes\Clothe):它是具体产品继承的父类(基类)。
具体产品类(NiKeShoes\NiKeClothe):具体工厂所创建的对象,就是此类。
优点与不足:
优点: 提供一个接口,可以创建多个产品族中的产品对象,同一类的多个产品对象不需要创建多个工厂。
缺点: 相比简单工厂模式而言,抽象工厂模式需要更多的类定义。
案例:
抽象产品类+具体产品类
// 基类 衣服
class Clothe
{
public:
virtual void Show() = 0;
virtual ~Clothe() {}
};
// 基类 鞋子
class Shoes
{
public:
virtual void Show() = 0;
virtual ~Shoes() {}
};
// 耐克衣服
class NiKeClothe : public Clothe
{
public:
void Show()
{
std::cout << "我是耐克衣服,时尚我最在行!" << std::endl;
}
};
// 耐克鞋子
class NiKeShoes : public Shoes
{
public:
void Show()
{
std::cout << "我是耐克球鞋,让你酷起来!" << std::endl;
}
};
抽象工厂类+具体工厂类
// 总厂
class Factory
{
public:
virtual Shoes *CreateShoes() = 0;
virtual Clothe *CreateClothe() = 0;
virtual ~Factory() {}
};
// 耐克生产者/生产链
class NiKeProducer : public Factory
{
public:
Shoes *CreateShoes()
{
return new NiKeShoes();
}
Clothe *CreateClothe()
{
return new NiKeClothe();
}
};
主函数可以通过调用一个工厂的不同方法类做不同的操作
int main()
{
// ================ 生产耐克流程 ==================== //
// 开设耐克生产线
Factory *niKeProducer = new NiKeProducer();
// 耐克生产线产出球鞋
Shoes *nikeShoes = niKeProducer->CreateShoes();
// 耐克生产线产出衣服
Clothe *nikeClothe = niKeProducer->CreateClothe();
// 耐克球鞋广告喊起
nikeShoes->Show();
// 耐克衣服广告喊起
nikeClothe->Show();
// 释放资源
delete nikeShoes;
delete nikeClothe;
delete niKeProducer;
return 0;
}应用案例:
SPDLOG生产不同级别的日志对象时使用工厂模式
模式7:责任链
简介 1、责任链模式 (Chain of Responsibility):为解除请求的发送者和接收者之间耦合,而使多个对象都有机会处理这个请求。将这些对象连成一条链,并沿着这条链传递该请求,直到有一个对象处理它为止。
2、责任链模式 (Chain of Responsibility)应用场景包括但不限于: 2.1、当有多个对象可以处理同一个请求时,具体哪个对象处理该请求由运行时刻自动确定。 2.2、当你想在不明确指定接收者的情况下,向多个对象中的一个提交一个请求时。 2.3、当你想在不必指定具体接收者的前提下,向一个或多个对象发出请求时。
3、责任链模式 (Chain of Responsibility)的构成 3.1、抽象处理者(Handler):定义一个处理请求的接口,包含一个处理请求的抽象方法和一个指向下一个处理者的引用。
class Logger
{
public:
Logger(LogLevel level);
void setNext(std::shared_ptr<Logger> nextLogger);
void logMessage(LogLevel level, const std::string& message);
virtual void write(const std::string& message) = 0;
protected:
LogLevel logLevel;
std::shared_ptr<Logger> next;
};
3.2、具体处理者(Concrete Handler):实现抽象处理者的方法,判断能否处理请求,如果能够处理请求则进行处理,否则将请求传递给下一个处理者。
class InfoLogger : public Logger
{
public:
InfoLogger(LogLevel level);
void write(const std::string& message);
};
4、责任链模式 (Chain of Responsibility)的优点 4.1、减少耦合度:它将请求的发送者和接收者解耦。 4.2、增强了对象的责任:通过改变链内的成员或调整它们的顺序,允许动态地新增或删除责任。 4.3、增加了灵活性:可以在运行时改变链中处理者的顺序和数量。 4.4、简化对象:对象只需要知道如何将请求发送到链上,而不需要知道链的结构细节。 4.5、分布请求处理:可以让多个对象都有机会处理请求,从而将单个请求的处理分散到多个类中。
5、责任链模式 (Chain of Responsibility)的缺点 5.1、请求可能未被处理:在某些情况下请求可能会到达链的末尾都没有被处理。 5.2、性能问题:由于请求的处理经过多个对象,可能会影响性能。 5.3、复杂性增加:系统设计更加复杂,需要维护链中的顺序。 5.4、调试难度大:由于请求在链中传递的过程中可能会变得难以追踪,使得问题难以定位。
案例:
1.定义
// 日志级别常量
enum LogLevel {
NONE = 0,
INFO = 1,
DEBUG = 2,
WARNING = 3,
ERROR = 4
};
// 抽象基类
class Logger
{
public:
Logger(LogLevel level);
void setNext(std::shared_ptr<Logger> nextLogger);
void logMessage(LogLevel level, const std::string& message);
virtual void write(const std::string& message) = 0;
protected:
LogLevel logLevel;
std::shared_ptr<Logger> next;
};
// INFO级别的日志处理者
class InfoLogger : public Logger
{
public:
InfoLogger(LogLevel level);
void write(const std::string& message);
};
// DEBUG级别的日志处理者
class DebugLogger : public Logger
{
public:
DebugLogger(LogLevel level);
void write(const std::string& message);
};
// WARNING级别的日志处理者
class WarningLogger : public Logger
{
public:
WarningLogger(LogLevel level);
void write(const std::string& message);
};
// ERROR级别的日志处理者
class ErrorLogger : public Logger
{
public:
ErrorLogger(LogLevel level);
void write(const std::string& message);
};
2.实现
Logger::Logger(LogLevel level) : logLevel(level)
{
}
void Logger::setNext(std::shared_ptr<Logger> nextLogger)
{
next = nextLogger;
}
void Logger::logMessage(LogLevel level, const std::string& message)
{
if (logLevel <= level)
{
write(message);
}
if (next)
{
next->logMessage(level, message);
}
}
InfoLogger::InfoLogger(LogLevel level) : Logger(level)
{
}
void InfoLogger::write(const std::string& message)
{
if (logLevel == LogLevel::INFO)
{
std::cout << "Info: " << message << std::endl;
}
}
DebugLogger::DebugLogger(LogLevel level) : Logger(level)
{
}
void DebugLogger::write(const std::string& message)
{
if (logLevel == LogLevel::DEBUG)
{
std::cout << "Debug: " << message << std::endl;
}
}
WarningLogger::WarningLogger(LogLevel level) : Logger(level)
{
}
void WarningLogger::write(const std::string& message)
{
if (logLevel == LogLevel::WARNING)
{
std::cout << "Warning: " << message << std::endl;
}
}
ErrorLogger::ErrorLogger(LogLevel level) : Logger(level)
{
}
void ErrorLogger::write(const std::string& message)
{
if (logLevel == LogLevel::ERROR)
{
std::cout << "Error: " << message << std::endl;
}
}
3、调用
auto infoLogger = std::make_shared<InfoLogger>(LogLevel::INFO);
auto debugLogger = std::make_shared<DebugLogger>(LogLevel::DEBUG);
auto warningLogger = std::make_shared<WarningLogger>(LogLevel::WARNING);
auto errorLogger = std::make_shared<ErrorLogger>(LogLevel::ERROR);
infoLogger->setNext(debugLogger);
debugLogger->setNext(warningLogger);
warningLogger->setNext(errorLogger);
// 构建完整的责任链,从INFO到ERROR
infoLogger->logMessage(LogLevel::INFO, "This is an informational message.");
std::cout << std::endl;
infoLogger->logMessage(LogLevel::DEBUG, "This is a debug message.");
std::cout << std::endl;
infoLogger->logMessage(LogLevel::WARNING, "This is a warning message.");
std::cout << std::endl;
infoLogger->logMessage(LogLevel::ERROR, "This is an error message.");
应用案例:
Nginx高性能网关(+openresty)
模式8:装饰器
定义:装饰器(Decorator)模式是一种结构型设计模式,它允许你动态地给一个对象添加额外的职责。
使用场景: 装饰器模式主要用于扩展对象的功能,而又不改变其原有结构。在C++中,装饰器模式主要应用于那些需要为对象动态添加功能或改变行为的场景,而这些附加行为是可以独立于基础组件的。
优点:
不需要修改源代码就能拓展对象功能
组件:
装饰器模式通常包含以下几个组件:
(1)组件(Component):定义一个对象接口,可以给这些对象动态地添加职责。
(2)具体组件(ConcreteComponent):实现组件接口,是被装饰器装饰的对象。
(3)装饰器(Decorator):实现与组件相同的接口,它包含一个指向组件对象的指针(或者引用),并可以在调用组件的方法之前或之后添加一些额外的功能。
(4)具体装饰器(ConcreteDecorator):实现装饰器接口,并添加一些额外的职责。举例分析:
假设定义了animal接口类,并具体定义了三个具体的动物。
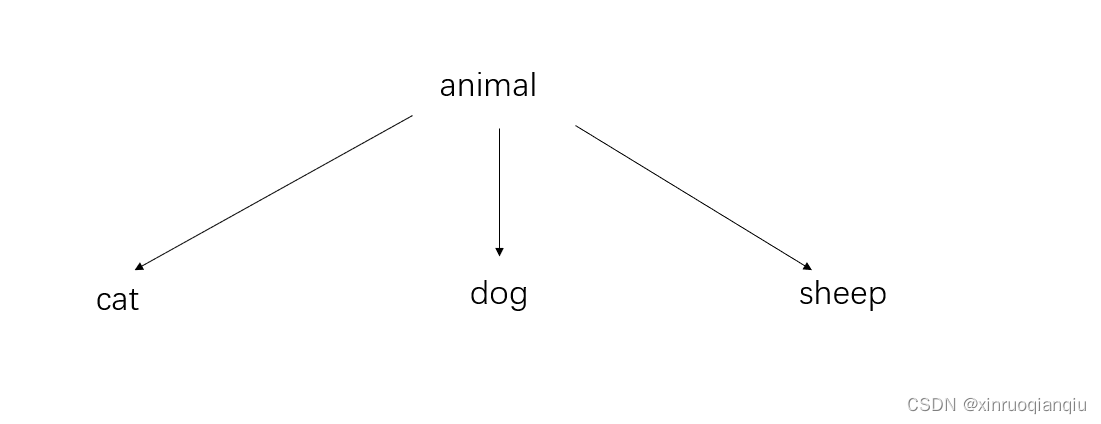
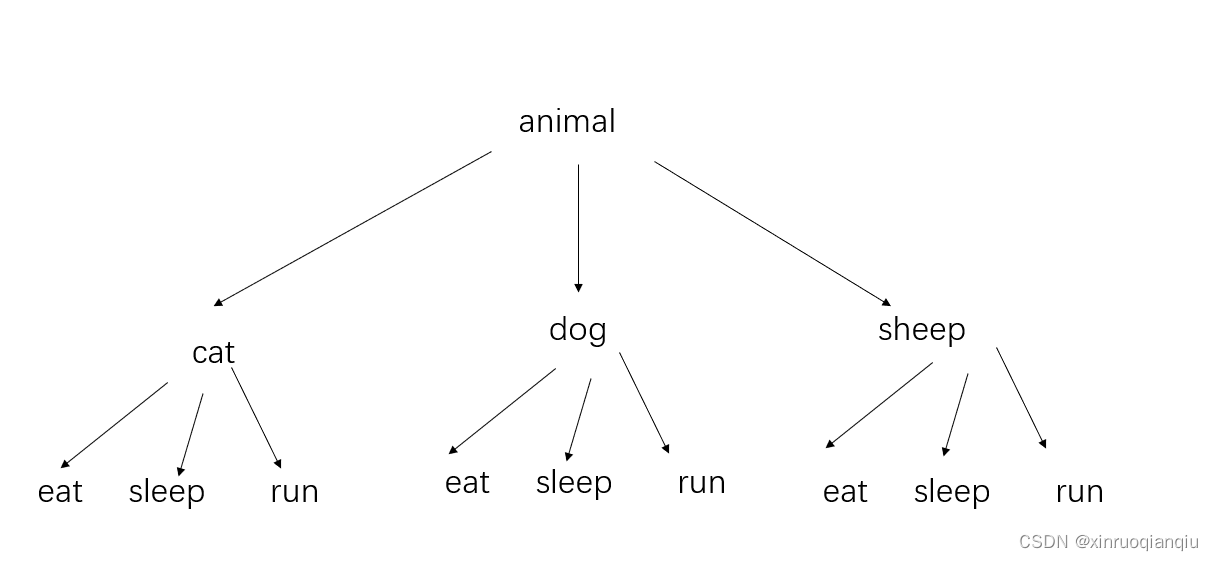
另外需要给每个动物增加三个功能——吃饭、睡觉、跑步;我们该如果设计类关系?
(1)为每个动物设计三个功能子类;
(2)使用装饰器,在animal下增加一个功能类;
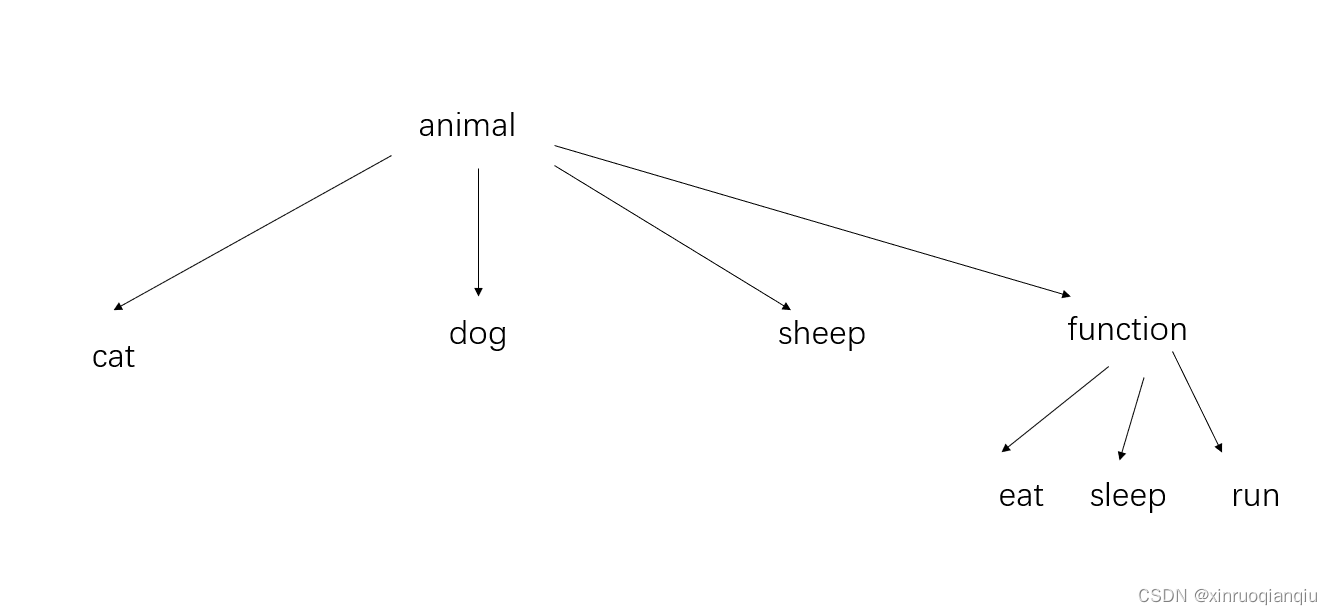
案例:
#include <iostream>
// 组件接口类
class animal
{
private:
public:
virtual void show() = 0;
};
// 具体组件,子类
class cat :public animal
{
private:
public:
void show() override
{
std::cout << "this is cat!" << std::endl;
}
};
// 具体组件,子类
class dog :public animal
{
private:
public:
void show() override
{
std::cout << "this is dog!" << std::endl;
}
};
// 具体组件,子类
class sheep :public animal
{
private:
public:
void show() override
{
std::cout << "this is sheep!" << std::endl;
}
};
// 装饰器
class animal_function :public animal {
public:
animal_function(animal* animal_ptr) :_animal_ptr(animal_ptr) {};
void show() override {
if (_animal_ptr != nullptr) {
_animal_ptr->show();
}
}
protected:
animal* _animal_ptr;
};
// 具体装饰器 eat
class eat_function : public animal_function {
public:
eat_function(animal* cc) : animal_function(cc) {}
void show() override {
std::cout << "eat_function before" << std::endl;
animal_function::show();
std::cout << "eat_function after" << std::endl;
}
};
// 具体装饰器 sleep
class sleep_function : public animal_function {
public:
sleep_function(animal* cc) : animal_function(cc) {}
void show() override {
std::cout << "sleep_function before" << std::endl;
animal_function::show();
std::cout << "sleep_function after" << std::endl;
}
};
// 具体装饰器 run
class run_function : public animal_function {
public:
run_function(animal* cc) : animal_function(cc) {}
void show() override {
std::cout << "run_function before" << std::endl;
animal_function::show();
std::cout << "run_function after" << std::endl;
}
};
int main()
{
animal* cat_0 = new eat_function(new cat());
cat_0->show();
animal* dog_0 = new sleep_function(new dog());
dog_0->show();
animal* sheep_0 = new run_function(new sheep());
sheep_0->show();
return 0;
}结果
eat_function before
this is cat!
eat_function after
sleep_function before
this is dog!
sleep_function after
run_function before
this is sheep!
run_function after模式9:组合模式
组合模式(Composite Pattern)是一种结构性设计模式,允许将一组对象组织成树形结构以表示“部分-整体”的层次结构。使得用户对单个对象和组合对象的操作/使用/处理具有一致性。
透明组合模式的优点
一致的接口:客户端可以使用相同的方式处理单个对象和组合对象。
简化代码:减少了客户端代码的复杂性,便于管理和扩展。
灵活性:可以轻松地添加新的叶子或组合类。
透明组合模式的缺点
设计复杂性:需要设计一个抽象组件接口,可能导致过多的类。
性能开销:在某些实现中,可能会有额外的性能开销,特别是在树结构较深时。
透明组合模式的适用场景
需要表示“部分-整体”层次结构的场景,例如文件系统、组织结构等。
客户端需要统一处理单个对象和组合对象的场景。
1. 主要组成成分
抽象组件(Component):声明了叶子和组合对象的共同接口。
叶子组件(Leaf):实现了组件接口,代表树中的叶子节点。
组合组件(Composite):实现了组件接口,定义了叶子和子组件的行为,存储子组件。
代码结构:
逐步构建透明组合模式 透明组合模式允许客户端以统一的方式处理单个对象和组合对象。通过在基类中定义 Add 和 Remove 方法,组合对象可以自由添加和删除子对象。这种模式适用于需要处理树形结构的场景,提供了良好的灵活性和可扩展性。下面是如何逐步构建透明组合模式的示例。
定义抽象组件(Component) 首先,定义一个抽象基类 FileSystem,声明所有具体组件的接口。
//抽象父类FileSystem(抽象接口)
class FileSystem
{
public:
virtual void ShowName(int level) = 0; //显示名字,参数level用于表示显示的层级,用于显示对齐
virtual int Add(FileSystem* pfilesys) = 0; //向当前目录中增加文件或子目录
virtual int Remove(FileSystem* pfilesys) = 0;//从当前目录中移除文件或子目录
virtual ~FileSystem() {} //做父类时析构函数应该为虚函数
};实现叶子组件(Leaf) 接下来,创建一个表示文件的类 File,它继承自 FileSystem。
//文件相关类
class File :public FileSystem
{
public:
//构造函数
File(string name) :m_sname(name) {}
//显示名字
void ShowName(int level)
{
for (int i = 0; i < level; ++i) { cout << " "; } //显示若干个空格用与对齐
cout << "-" << m_sname << endl;
}
virtual int Add(FileSystem* pfilesys)
{
//文件中其实是不可以增加其他文件或者目录的,所以这里直接返回-1,无奈的是父类中定义了该接口,所以子类中也必须实现该接口
return -1;
}
virtual int Remove(FileSystem* pfilesys)
{
//文件中不包含其他文件或者目录,所以这里直接返回-1
return -1;
}
private:
string m_sname; //文件名
};实现组合组件(Composite) 接着,创建一个表示目录的类 Dir,它也继承自 FileSystem。
//目录相关类
class Dir :public FileSystem
{
public:
//构造函数
Dir(string name) :m_sname(name) {}
//显示名字
void ShowName(int level)
{
//(1)显示若干个空格用与对齐
for (int i = 0; i < level; ++i) { cout << " "; }
//(2)输出本目录名
cout << "+" << m_sname << endl;
//(3)显示的层级向下走一级
level++;
//(4)输出所包含的子内容(可能是文件,也可能是子目录)
//遍历目录中的文件和子目录
for (auto iter = m_child.begin(); iter != m_child.end(); ++iter)
{
(*iter)->ShowName(level);
}//end for
}
virtual int Add(FileSystem* pfilesys)
{
m_child.push_back(pfilesys);
return 0;
}
virtual int Remove(FileSystem* pfilesys)
{
m_child.remove(pfilesys);
return 0;
}
private:
string m_sname; //文件名
list<FileSystem*> m_child; //目录中包含的文件或其他目录列表
};主函数(Main) 在 main 函数中,创建文件和目录对象,并构建树形结构。
int main()
{
Dir* root = new Dir("root");
FileSystem* file1 = new File("common.mk");
FileSystem* file2 = new File("config.mk");
Dir* appDir = new Dir("app");
FileSystem* file3 = new File("nginx.c");
// 构建树形结构
root->Add(file1);
root->Add(file2);
root->Add(appDir);
appDir->Add(file3);
// 显示整个目录结构
root->ShowName(0);
// 释放资源
delete file3;
delete appDir;
delete file2;
delete file1;
delete root;
return 0;
}运行上述代码,输出结果如下:
+root
-common.mk
-config.mk
+app
-nginx.cUML
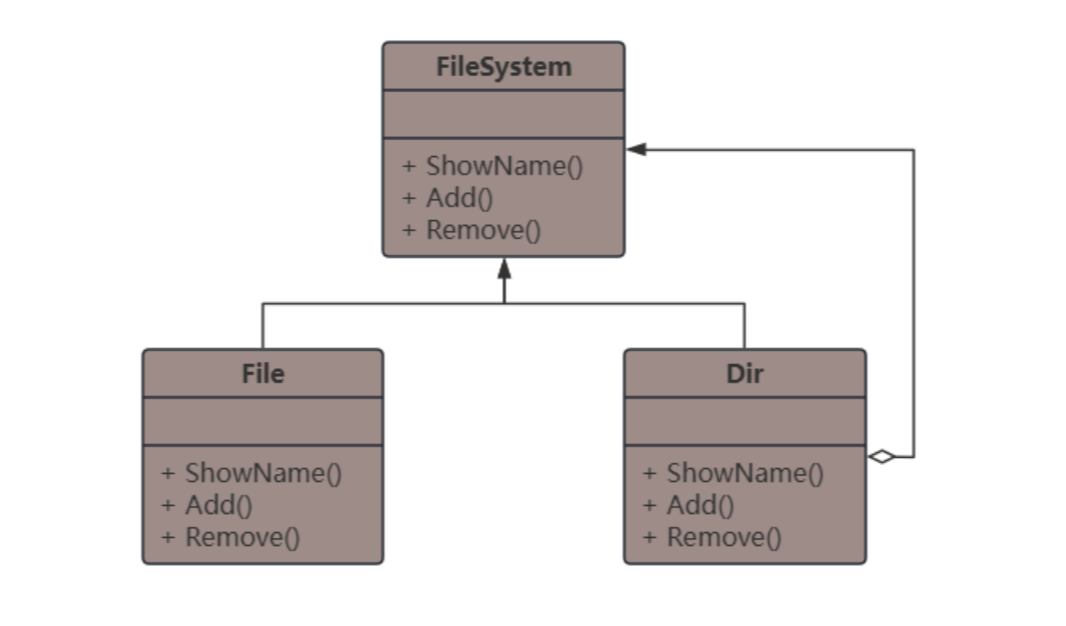
透明组合模式 UML 图解析
Component (抽象组件): 为树枝和树叶定义接口(例如,增加、删除、获取子节点等),可以是抽象类,包含所有子类公共行为的声明或默认实现体。这里指 FileSystem 类。
Leaf (叶子组件): 用于表示树叶节点对象,这种对象没有子节点,因此抽象组件中定义的一些接口(例如 Add、Remove)在这里没有实现的意义。这里指 File 类。
Composite (树枝组件): 用于表示一个容器(树枝)节点对象,可以包含子节点,子节点可以是树叶,也可以是树枝,其中提供了一个集合用于存储子节点(以此形成一个树形结构,可以通过递归来访问所有节点)。实现了抽象组件中定义的接口。这里指 Dir 类。